Current computer vision systems produce a large number of images, many of
which are never seen by humans. Yet, in order to understand, critique and
shape the impact of machines that can see in ways that exceed human vision
capability, humans will need to learn to see like machines, to understand
their abstractions and their categorizations of things in the world. The
title of the work refers to the measurement of perfect human vision (20/20),
which is contrasted with a yet unquantifiable measure of seeing
(specifically in a cultural context) for a computer vision system -
represented by the variable "X." Audience members are invited to
experience the process of seeing in a complex neural network based computer
vision system and determine the value of "X" for themselves. Based on an
advanced computer vision system developed by Dr. Eugenio Culurciello and
Alfredo Canziani in the School of Biomedical Engineering at Purdue University,
20/X explores visuality, representation and knowledge in the age of
intelligent seeing machines. Presented as either a freestanding observation
station or an immersive viewing apparatus, the installation provocatively
asks the question: do we need to acquire new literacy skills in an emerging
visual culture of computer vision?
Audience Experience
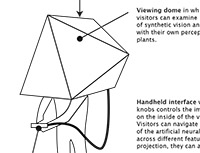
20/X reveals the process of machines looking at the world, leading
up to but not including the final classification and categorization of
objects in a live video feed. The interactive interface allows users to
trace the levels of abstraction employed by the algorithm—from coarse and
geometry driven in the beginning to more specific and detail-oriented in
the end at which point distinctive patterns, areas and objects that
"excite" the computer vision system can be identified. The authors
are interested in these processes before the final classification precisely
because they reveal the logic and strategies of the machine vision system,
thus helping humans to "see like a machine" rather than just
providing visitors with the almost magical technological feat of naming the
objects it sees in an image. While this is important for a different set
of applications, the authors believe that an experience of the system in
this more ambiguous form is most insightful to anyone who is interested in
learning to understand how machines see the world around us and anyone who
is interested in asking critical questions about this process or shaping it.